一、颠覆认知的实验结论:AI让资深开发者效率倒退
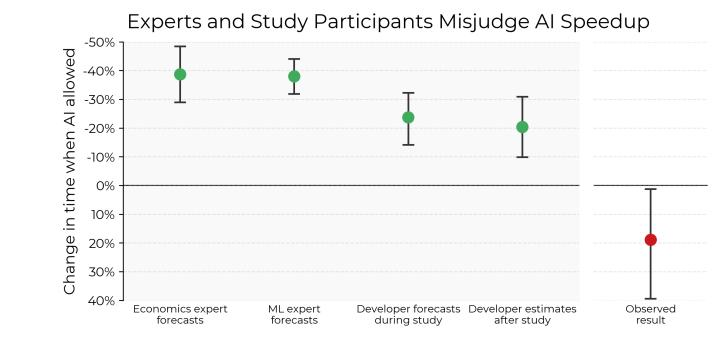
美国MIT附属机构METR研究所通过严格的随机对照实验(RCT),对16名高级开源开发者完成246个真实任务的全程追踪发现:使用AI编程工具(如Cursor Pro)的开发者平均耗时比传统方式增加19%。这一数据与开发者主观预测的”提速24%”形成尖锐对比,揭示了AI在核心编码环节的”效率陷阱”。

实验设计的关键在于:
- 双盲分组:任务随机分配至AI组与非AI组,排除任务难度干扰;
- 过程全记录:通过屏幕录制与时间戳分析,精确捕捉”主动编码””提示设计””AI审查”等环节耗时;
- 预期值校准:引入开发者对任务时长的预估值作为基准,量化”比预期多花的时间”。
结果显示,AI组开发者在提示工程(Prompt Engineering)、结果验证和错误修正上消耗了大量额外时间。例如,处理复杂逻辑时,开发者需反复调整提示词、拆分问题,并手动整合AI生成的碎片化代码,导致整体效率下降。
二、效率悖论的根源:AI重构了开发者的注意力分配
研究指出,AI并未真正优化”编码”这一核心环节,而是通过流程碎片化制造了”快感错觉”:
- 交互成本激增:开发者需花费30%-40%时间设计提示词、解析AI输出,甚至反复修正语义歧义;
- 认知负荷转移:原本集中的编码思维被拆解为”问题拆分→AI生成→人工筛选→整合”的多步骤流程;
- 心理节奏干扰:频繁切换任务(如等待AI响应、查阅文档)导致开发者产生”虚假忙碌感”。
一位参与实验的开发者坦言:”我以为AI能替我写代码,结果却在教它如何理解需求。”这种现象在大型开源项目中尤为显著——AI对隐含规则、历史代码上下文的理解不足,反而需要开发者投入更多时间”教AI做事”。
三、行业评估体系的漏洞:理想化测试误导技术认知
METR研究直指当前AI评估体系的根本缺陷:
- 基准测试(如SWE-Bench)的失真性:
- 情境孤立:测试题多为脱离项目背景的”玩具代码”;
- 无协作压力:忽略团队沟通、代码审查等真实开发约束;
- 无历史负担:不涉及遗留代码维护、技术债等复杂场景。
- 企业落地偏差:
实验表明,AI在快速原型设计中确有优势,但在成熟系统维护中可能降低效率。然而,当前市场宣传过度聚焦前者,掩盖后者的风险。
四、AI工具的真实价值:流程改造而非效率提升
研究提出,AI的真正意义可能在于重构开发范式:
- 降低技术门槛:非专业开发者可通过AI参与简单开发,但专业领域仍需人类主导;
- 改变协作模式:AI或将成为”代码初审者”,但最终决策仍依赖人类经验;
- 催生新职业分工:如”AI提示工程师””代码审查专家”等角色可能出现。
然而,这一转型代价高昂:企业需承担培训成本、流程重构风险,甚至可能因过度依赖AI导致核心技能退化。
五、争议与未来:AI编程工具的”泡沫”与机遇
该研究引发业界激烈讨论:
- 支持方认为实验揭示了AI的局限性,推动行业回归理性;
- 反对方质疑样本量不足(仅16名开发者),且未涵盖AI辅助设计的潜在价值。
未来方向:
- 开发更透明的AI评估框架,引入真实项目数据;
- 探索人机协作的”黄金比例”,如限定AI使用场景;
- 加强开发者培训,提升提示工程能力以减少交互成本。
结语
METR的实验像一面镜子,照出了AI狂热背后的冷峻现实:技术工具的价值从不在于”替代人类”,而在于如何与人类能力形成互补。当行业沉迷于”AI提速”的叙事时,或许更应追问:我们究竟在为什么买单?是真正的效率,还是一种数字化的自我安慰?